Analyze and fix structured data with Google testing tool
Recently I ported my blog from Hexo engine to Gatsby and as part of that migration I wanted to ensure that SEO is in the best state it can be. I added structured data markup throughout all my site a while ago and wanted to make sure that once migration is done - there are no errors. I took a note that I should verify this and moved on.
Migration process took longer than I expected (2 weeks) and I couldn't find time to verify if structure is still accurate. Finally, I finished most important part of migration and started to add small enhancements here and there. Following best practices, I run audit on my site using Lighthouse:
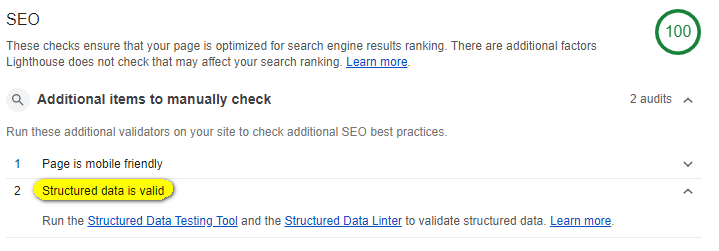
Even though SEO score is 100, there was a note that I should verify a couple things manually and one of them is structured data. One of the links was pointing to https://search.google.com/structured-data/testing-tool/, which is very useful for finding things I missed during migration.
Structured data tool results
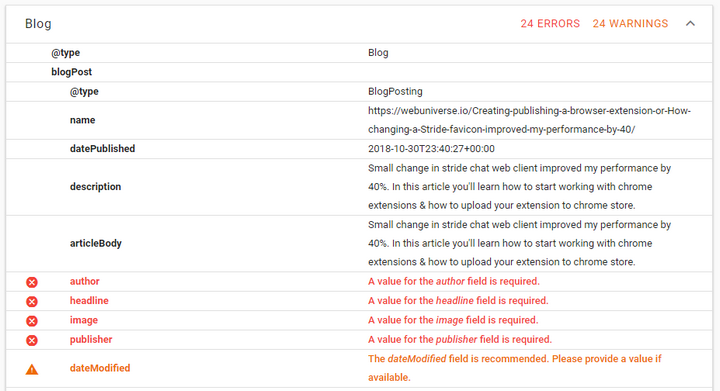
It would be great if a bit more information were provided about how issues can be fixed. A link to a section that gives more insights about missed/incorrect attributes would also be useful. But it is already great to know that something is wrong, so I can do my own research.
Examples from schema.org & improvements
On https://schema.org/docs/full.html you can get a full list of types. I found BlogPosting type and there is a link to information about author, but unfortunately there are no examples of how it should be specified. On my site home page, Blog type is nested under section with WebPage type, which has author type specified, so you would think that it could be inherited, but if linter complains there must be a reason. Most likely idea was that since each blog posting could be written by different people, you should specify author explicitly for each field. In my case this is not too convenient, but also not the end of the world. I didn't want to surface this redundant information to screen readers by adding this info and putting it off screen, so I used meta tags for things that should not be visible. For things that are already presented I used itemprop attributes:
<meta itemprop="author" content="Sergey" /><h1 itemprop="headline">Title of the post</h1><meta itemprop="image" content="https://path-to-image-or-default" /><meta itemprop="publisher" content="Author" /><meta itemprop="mainEntityOfPage" content="https://path-to-blog-root"/>
Another weird thing was that linter marked image field as required. This doesn't make much sense to me - why can't I have posts without images (I do have some like that!)? So, in this case I'm falling back to a default image even though it is not really surfaced anywhere, but if that will make google search tool happier, I can do that.
New results after those improvements look better:
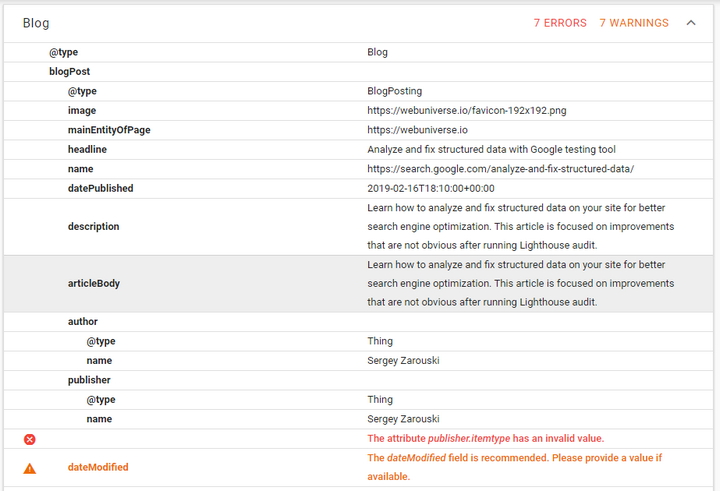
We can see that number of issues reduced, but there is something weird about author & publisher fields. They are both marked as Thing type (which is a parent type for Person, but this is still weird) and there is also that issue The attribute publisher.itemtype has an invalid value. It felt that problem was due to Thing type, but after change to Person like below publisher.itemtype error still didn't go away.
<div itemprop="author" itemscope itemtype="http://schema.org/Person"><meta itemprop="name" content={author} /></div><div itemprop="publisher" itemscope itemtype="http://schema.org/Person"><meta itemprop="name" content={author} /></div>
I found another Google document that says that publisher should be of Organization type - https://developers.google.com/search/docs/data-types/article. It is a bit annoying as schema.org says that publisher type can be either Person or Organization - https://schema.org/publisher. I guess google has different thoughts about how things should be structured. Following change improved things:
<div itemprop="author" itemscope itemtype="http://schema.org/Person"><meta itemprop="name" content="Sergey" /></div><div itemprop="publisher" itemscope itemtype="http://schema.org/Organization"><meta itemprop="name" content="Web Universe" /></div>
But now there was a new error: A value for the logo field is required. And after that one there was another one about logo.url field. So final working result end up looking something like following:
<div itemprop="blogPost" itemscope itemtype="http://schema.org/BlogPosting"><div><meta itemprop="image" content="image"/><div itemprop="author" itemscope itemtype="http://schema.org/Person"><meta itemprop="name" content="author" /></div><div itemprop="publisher" itemscope itemtype="http://schema.org/Organization"><meta itemprop="name" content="siteTitle" /><div itemprop="logo" itemscope itemtype="https://schema.org/ImageObject"><meta itemprop="url" content="siteLogo" /></div></div><meta itemprop="mainEntityOfPage" content="siteUrl"/><h3 itemprop="headline">...</h3><time datetime="date" itemprop="datePublished">...</time></div><div itemprop="description articleBody">...</div></div>
Takeaway - don't assume search will understand data structure on its own
I'm not too happy about end result - there are a lot of empty divs and meta tags that I thought are not necessary because I thought that if information exists somewhere on the page - search engine will be smart enough to process it properly and inherit some types. My takeaway for this work is that I had a lot of assumptions and it is good that such a tool exists that can help you to really find how your data is structured and what you can do to help it be recognized better.
Do you use this tool for your site? If no, do you take other steps to ensure that data is represented correctly to search engine?
Don't use empty divs/meta - json-ld is much better
Update March 2, 2019: Working on something you're not too familiar with - certainly helps to learn new things and why they exist/work in a certain way. Adding pseudo markup to tell about page structure didn't make much sense to me and it hit me why json-ld format exists. It helps to define page structure without invisible markup - which makes a lot of sense! Something pretty obvious when you realize it, but at the time when I was writing this I was following what I did in 2015 & just wanted to satisfy validator. I'm not going to update markup for some time as I achieved what I wanted and there are other improvements I would like to work on, but refactoring with json-ld definitely goes into backlog for my site. Hopefully this update will make it easier for you to deal with structured data on your site. Or if you already know that and this seems too obvious I hope you smiled - so it worth writing this anyway =). Good day.
Thank you for reading! =)